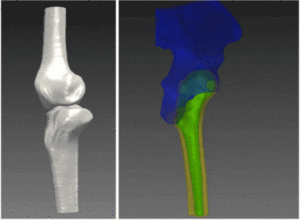
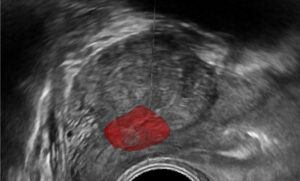
Image and object recommender systems have been developed along with the Internet itself. The recommender systems are constructed to assist user’s navigation through the variety of content and products (videos, images or objects sold on a website) by correlating user preferences with the item’s characteristics. Sites containing huge amounts of content must necessarily suggest a narrow list, limited to a set of few linked items of interest to the user; the cost of not doing that would involve loss of users, confused by the difficulty to get access to relevant content. As an example, the eBay website hosts more than 800 million items (as of 2015) with over 11 million user searches every hour. Therefore, recommender systems can be seen as an automatic generation of personalized search preferences, with the goal of maintaining the balance between targeted suggestions (thus increasing potential profitability) and user experience.
Recommendation of an item to a user is performed most commonly by calculating the distance between user preferences and activity on one side and properties of inventory objects on the other. The distance is calculated between the vector of tags, interest, recent and long history of user activity and compared to the vector of object’s tags. Most frequently object tags for items in the inventory are inserted manually, a laborious and time consuming task. Machine learning and classifiers are being frequently utilized to create automatic semantic tagging and offer targeted suggestions based on the calculated measure of distances.
Recommendation of an item to a user is performed most commonly by calculating the distance between user preferences and activity on one side and properties of inventory objects on the other. The distance is calculated between the vector of tags, interest, recent and long history of user activity and compared to the vector of object’s tags. Most frequently object tags for items in the inventory are inserted manually, a laborious and time consuming task. Machine learning and classifiers are being frequently utilized to create automatic semantic tagging and offer targeted suggestions based on the calculated measure of distances.

Machine vision and image processing techniques have greatly improved over the past decade to the point where scene analysis and automatic tagging of it become feasible, computationally acceptable and fast as well. Automatic extraction of features from a given image helps recommender systems place the inspected item in the right set of categories or at least into one which can be considered a good enough initial guess.
The automatic extraction of features from images is then called to tag the scene in a manner which is close to the human perception of it. For example, image features might include landscape at dusk or broad day time, human or animal interactions, textured image and so on. To this purpose, computer vision algorithms need first to extract salient features of the image and then cluster them according to semantically meaningful groups.
Region growing techniques are utilize to subdivide the image into non-overlapping regions containing salient features. The edge map of the image (in all color channels) is used to determine stiff boundaries for region growing and peaks of the edge distance-transform are used as initial seeds for the process. Analysis of each segmented region allows us to extract information regarding its shape (using boundary shape descriptors), its color, texture, and its relationship to neighboring regions.
Neural networks and support vector machine type of classifiers are then utilized in a supervised learning manner to assign high-order contextual tagging to each segmented region based on its extracted features. Once a classifier is trained, the system is able to categorize segmented regions into semantic meaningful categories. As humans, in order to be able to understand a scene we assign meaningful tags to regions based on their association rather than in isolation. Similarly, a mere automatic classification of objects, say an image including water and a mountain, does not guarantee that the system will automatically tag the scene as showing a waterfall. The mutual relationship between the object has to be sorted out.
High-order conceptual associations between objects in a scene requires sophistication in the training process. For a reliable automatic scene understanding and tag assignment by machine learning classifiers, the input (i.e. segmented region and extracted features) has to be as indicative as possible, including the salient features of the image. This is key for an optimal automatic semantic tagging.
RSIP Vision is an expert in image processing computer vision and machine learning techniques. If you want to construct a cutting edge recommender systems to work with your products, you need real vision experts like RSIP Vision’s engineers. Contact us now and we will help you develop your recommender system.
The automatic extraction of features from images is then called to tag the scene in a manner which is close to the human perception of it. For example, image features might include landscape at dusk or broad day time, human or animal interactions, textured image and so on. To this purpose, computer vision algorithms need first to extract salient features of the image and then cluster them according to semantically meaningful groups.
Region growing techniques are utilize to subdivide the image into non-overlapping regions containing salient features. The edge map of the image (in all color channels) is used to determine stiff boundaries for region growing and peaks of the edge distance-transform are used as initial seeds for the process. Analysis of each segmented region allows us to extract information regarding its shape (using boundary shape descriptors), its color, texture, and its relationship to neighboring regions.
Neural networks and support vector machine type of classifiers are then utilized in a supervised learning manner to assign high-order contextual tagging to each segmented region based on its extracted features. Once a classifier is trained, the system is able to categorize segmented regions into semantic meaningful categories. As humans, in order to be able to understand a scene we assign meaningful tags to regions based on their association rather than in isolation. Similarly, a mere automatic classification of objects, say an image including water and a mountain, does not guarantee that the system will automatically tag the scene as showing a waterfall. The mutual relationship between the object has to be sorted out.
High-order conceptual associations between objects in a scene requires sophistication in the training process. For a reliable automatic scene understanding and tag assignment by machine learning classifiers, the input (i.e. segmented region and extracted features) has to be as indicative as possible, including the salient features of the image. This is key for an optimal automatic semantic tagging.
RSIP Vision is an expert in image processing computer vision and machine learning techniques. If you want to construct a cutting edge recommender systems to work with your products, you need real vision experts like RSIP Vision’s engineers. Contact us now and we will help you develop your recommender system.