David Menashe, Arie Rond, Ilya Kovler
Introduction
In recent years, artificial intelligence (AI) has revolutionized many fields and has had a major impact on our daily lives. This revolution is driven by a combination of advanced deep learning models and an abundance of accessible training data on the internet.
In the medical field, despite its huge potential, the adoption of AI has proceeded at a much slower pace. This is due to a combination of challenges which are unique to the medical field, and can be broadly classified as follows:
- Data and Annotation Challenges, relating to the acquisition and labeling of extensive, diverse, and high-quality datasets.
- Development and Technological Challenges, relating to the need for a deep understanding of the clinical application, and for a high level of model accuracy and robustness.
- Regulation and Clinical Adoption Challenges, relating to the need to comply with regulatory requirements, and to overcome reluctance and lack of trust in the medical establishment.
In this paper, we focus on data and annotation challenges, and describe the strategies we have developed at RSIP Vision to mitigate these challenges.
Data Challenges
As with all AI applications, medical AI models require large amounts of varied and high-quality data for training. However, in addition to the normal data requirements for AI, there are also requirements that are specific to medical AI:
- Precision and data integrity: Medical AI models are typically targeted at very specific applications and have a limited scope, for example, classification of tumors in breast Ultrasound (US) imaging. In contrast, other AI models, such as for autonomous vehicles, need to deal with a very wide range of objects and environments. This dictates different data requirements for each type of model. Unlike generic AI applications, where large volumes of data can often compensate for noise and variability, medical AI necessitates highly accurate, clean, and specific datasets. Errors or inconsistencies in medical data can lead to incorrect diagnoses or treatment recommendations, which can have serious implications.
- Extensive Diversity: Even though medical AI models typically have a limited scope, it is still necessary to ensure a high level of diversity in the data used for training. Taking the above example of classification of tumors in breast US, the model would need to deal with:
- US related variations, such as different processors, probes, settings, acquisition protocols, etc.
- Patient anatomy variations, such as age, breast texture, breast size, etc.
- Pathology related variations, such as different tumor types, different tumor sizes, different locations of the tumor, different surrounding tissue, etc.
All these variations, as illustrated in Figure 1, need to be reflected in a balanced and representative manner in the data used to train the model.

Key Obstacles in Data Acquisition
A number of factors pose a challenge to fulfilling the general and specific data requirements for medical AI:
- Regulatory Constraints: The medical field is heavily regulated in general, and this also applies to data acquisition. Some data, such as endoscopic and laparoscopic video, require invasive procedures. Other data, such as CT and X-ray, involve potentially harmful radiation. Such data can only be acquired when there is sufficient medical justification for it. Data related to new medical devices is particularly challenging to collect, due to the long regulatory process required to approve these devices for clinical use.
- Cost: Acquiring medical data often requires highly skilled clinical and technical personnel, as well as significant capital investment and operating expenses. Buying and installing a single MRI machine can cost millions of dollars, while operating expenses for a single machine can be a few hundred thousand dollars per year. Highly skilled and well trained staff are also needed to operate the machine.
- Patient privacy, consent, and security: When handling medical data, it is often necessary to anonymize the data, and ensure it is secured. Some data may also require specific patient consent to be used to train AI models.
- Fragmented healthcare infrastructure: Most medical data is collected by private or non-governmental healthcare providers. The data is often stored locally, and accessing the data requires specific, complex, and time-consuming arrangements and contracts with each institution.
- Partial, erroneous, and low-quality data: Not all medical data is stored for future use. For example, intra-op fluoroscopy data may only be used during a procedure and discarded afterwards. Other data is stored, but without important necessary associated meta-data, such as patient demographics or clinical context. In some cases meta-data is stored, but erroneously. In other cases, data is of low quality and cannot be used to train AI models. For example, while ultrasound is relatively widespread, safe, and inexpensive, its acquisition remains inconsistent due to high user dependency. Acquiring good quality US data requires experienced technicians using high-quality and well-maintained equipment.
- Complexity: The process of collecting medical data is complex due to the diversity of the data itself, which includes various modalities (MRI, CT, X-ray, US, OCT, video), data formats, equipment manufacturers and models, protocols, physical environments, staff expertise levels, patient anatomy, and medical conditions.
Risks Associated with Data Acquisition in Medical AI
The challenges associated with data acquisition for Medical AI model development can result in several significant risks. Here are some of the concerns:
- Insufficient data available for training can hinder the development of robust AI models.
- Poor-quality data may lead to inaccurate or unreliable output, as in “garbage in, garbage out”.
- A lack of diversity in the training data can harm the model’s ability to generalize, leading to overfitting on specific populations, conditions, devices, or acquisition environments.
- The model will require significant changes to perform well on next-gen device data.
Mitigation Strategies
To overcome these risks, RSIP Vision has adopted and fine tuned various mitigation strategies in the more than 10 years that we have been developing medical AI models:
- Involving clinical experts from the start: As we will see in the next section, close collaboration with clinical experts is critical for high-quality medical data annotation. However, even before the annotation stage, clinical experts can contribute significantly in determining the various data types and parameters that should be considered, as well as reviewing and filtering the data before it is annotated.
- Dedicated in-house data team: Having an in-house data team is critical to developing and maintaining knowledge and experience in acquiring and using medical data. It facilitates efficient data collection while ensuring a strong focus on AI model requirements.
- Medically informed data augmentation: While data augmentation is a well known technique used in AI, simply applying standard augmentation methods to medical data is insufficient. Some standard augmentations are irrelevant to specific medical data modalities, while others need to be specifically tailored for each modality. For example, adding noise and artifacts to US data is inherently different compared to adding noise and artifacts to CT data.
- Data harmonization / normalization: Carefully pre-processing data before training and prediction can help make the trained model more robust and improve performance on edge cases. Applying this method successfully requires deep knowledge of the data modality and acquisition protocols for which the AI model is being trained.
- Domain adaptation: In many cases, data from a different domain, even a non-medical domain, may be used to boost the performance of an AI model. For example, models pre-training on standard abundant non-medical image data may be integrated into models targeted for US data. In another example, CT data may be used for models targeting MRI data, and vice versa. Successfully applying domain adaptation requires deep knowledge of the source and target domains, as well as significant experience navigating various pitfalls associated with domain adaptation.
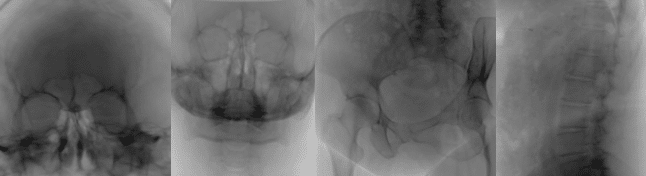
- Synthetic data generation: Even after applying all the above strategies, the available medical data may simply not be sufficient to train a model robust and accurate enough to be deployed in a real world clinical scenario. In such cases, generating high-quality synthetic data can be critical to the success of a medical AI project. Synthetic data generation can range from modifying existing data to creating completely new cases. One example of modifying existing data involves artificially inserting metallic objects, such as screws, into existing X-Rays and CTs. Another example is the use of advanced physical modeling to insert artifacts such as acoustic shadowing and mirror images into real US images. In both examples, the resulting synthetic data helps improve model performance in the presence of realistic artifacts. On the other end of the scale, completely new data can be generated using physical modeling and/or generative AI. For example, cross-sections from CT scans can be used to generate 2D X-ray like images, and then processed with a diffusion model or StyleGAN to generate realistic fluoroscopy images, as shown in Figure 2. In another example, advanced 3D modeling using real CT-based anatomy can be used to create synthetic gastroscopic videos.
- AI model optimization: By carefully tailoring the size of a deep learning model, as well as using regularization and dropout techniques, it is possible to improve model performance with smaller datasets.
- Efficient use of data: Carefully balanced datasets can significantly reduce the overall amount of data used in training. Having a large amount of one specific type of data compared to others is inefficient and even detrimental. Using cases which cover a wide range of edge variations can also increase efficiency. For example, incorporating a case acquired using relatively rare equipment, with a relatively rare patient anatomy and rare disease simultaneously addresses multiple data deficiencies.
- Building long-term relationships with data providers: Setting up and maintaining -long-term relationships with multiple data providers can ensure access to a large quantity of varied high-quality medical data. These providers can take care of anonymization, security, and patient consent, and can also assist in navigating the complexity of the data and filtering out irrelevant or low-quality data. Data costs can also be reduced when working with large quantities.
Annotation Challenges
AI models generally use large amounts of training data and therefore can tolerate a certain level of annotation errors and inaccuracies. In contrast, medical AI models are usually trained with relatively small datasets, as seen in the previous section, and therefore the weight of each data item is more pronounced. This means that careful and precise annotation of as many data items as possible is critical to the success of the model.
Not only is a much higher level of accuracy required in medical data annotation, but there are also unique challenges that need to be overcome to achieve this:
- Clinical expertise: Annotating everyday objects such as cars, bicycles, and people requires minimal skill and training. On the other hand, annotating medical data requires training and practice, as well as a certain level of understanding of both the clinical application and the data modality. For example, annotating the left atria in an echocardiogram requires not only an understanding of cardiac anatomy, but also a general understanding of US imaging in order to identify artifacts and discern features.
- Subjectivity: Even amongst clinical experts there may be differences in annotations. In some cases, the agreement between different clinical experts can be as low as 70%. Such disagreement can result from the subtle nature of the data. For example, defining an accurate tumor boundary in an US image may be difficult and open to interpretation. Disagreement can also arise from using different, evolving, or ambiguous medical standards and definitions. These very same factors can even lead to inconsistencies in the annotations of the same clinical expert over time.
- Complexity: Medical annotations often require pixel-level accuracy. For example, if we wish to train an AI model to segment bones and joints for knee arthroplasty planning, the resulting model should provide sub-mm level accuracy in order to design the required implants. In order to achieve this accuracy, the annotations also need to be very accurate at the pixel level. Another level of complexity is added by the fact that many medical imaging modalities are 3D, such as CT and MRI. When annotating 3D structures, it is very important to be consistent across slices, and even to use different views (sagittal, axial, coronal) during the annotation process.
- Lack of standard automation tools: Today, advanced automation tools can help to streamline the annotation process for everyday objects. However, such tools seldom work well enough with medical data. Even where such tools exist, a high level of manual annotation is still required to achieve the desired accuracy.
Risks Associated with Data Annotation in Medical AI
The challenges linked to data annotation for developing medical AI models can lead to several significant risks. Here are some key concerns:
- The annotation process can be prohibitively time-consuming and costly.
- Incorrect labeling can lead to inaccurate or unreliable output, again “garbage in, garbage out”.
- Inconsistent data annotation can negatively impact the ability of the model to learn, possibly requiring more data than would otherwise be necessary.
- The annotation process can be inefficient, leading to a waste of resources.
Mitigation Strategies
The strategies we have developed to overcome these risks include:
- Deep involvement of clinical experts: Over the years, RSIP Vision has developed strong working relations with experts in different medical fields, such as Radiology, Cardiology, Urology, Ophthalmology, etc. These experts provide crucial advice and training in the early stages of the annotation process, and also serve as the final authority for difficult or ambiguous cases. The experts also take part in the ongoing review process to ensure the integrity of the annotations. In many cases more than one clinical expert is assigned to a project in order to reduce the subjectivity and ensure the annotations are aligned with the broadest possible medical consensus.
- In-house annotation team: Our in-house annotation team consists of senior medical students before their internship. These students have broad medical knowledge which allows them to receive training and guidance from the clinical experts and then to carry out the annotation tasks in the best possible manner. The students are also highly motivated, since participation in the projects provides them with valuable experience. The team is headed by a full-time permanent manager whose responsibilities include consolidating and documenting the knowledge and experience gained in each project.
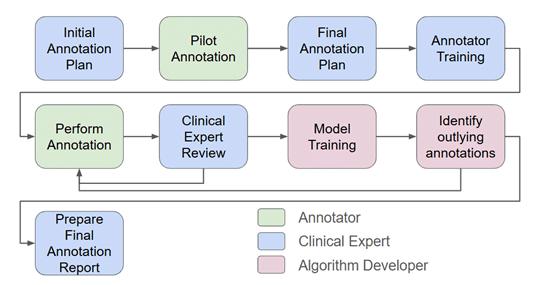
- Rigorous annotation procedures: All projects adhere to a rigorous annotation procedure, as shown in Figure 3, which includes developing an initial plan with the clinical expert, performing a pilot annotation, training the annotators, initial and periodic reviews for each annotator, and weekly meetings to discuss difficult and ambiguous cases and to share knowledge between the team. The annotation process itself is carefully documented and versioned.
- Customized annotation tools: Due to the lack of standard automation tools that can handle medical data, it is often necessary to customize tools to work with specific types of data. These tools can range from relatively simple GUIs, to complex AI models which provide an initial annotation that is then reviewed and manually corrected by an annotator.
- Minimizing annotation requirements: As discussed in the previous section, medical datasets are usually relatively small. However, in some cases, the required annotations may be so labor intensive that it is impractical to annotate all the available data. In such cases, many of the strategies described in the previous section, such as domain adaptation and synthetic data, can also be applied to reduce the annotation requirements.
- Iterative annotation process: Using an iterative approach to annotations provides an efficient strategy for achieving accurate final results while minimizing the required effort. After the initial iteration of annotation and model training, in depth statistical analysis of the results can reveal cases where the annotations need to be improved. Effort is then focused on improving annotation for these cases, followed by a new round of training. This process can be repeated until the improvement saturates (see figure 3).
Conclusion
While AI models for medical applications hold immense promise, significant challenges related to data and annotation, amongst others, exist. By developing and applying tried and tested mitigation strategies as described in this article, these challenges can be effectively managed.