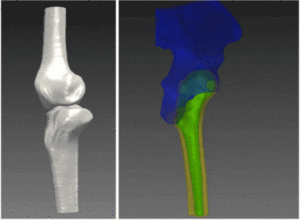
Hardware for three-dimensional surface reconstruction
Depth cameras are equipped with two or more light sensors placed at a small distance apart, and an optional infrared projector. The depth in a scene is computed by triangulation, incorporating the principles of stereo vision. The output depth image provides the distance of all objects in the scene from the sensors’ axis. Commercial depth cameras now offers depth information ranging from 0.2 to 10 m, and provide a much richer data than that of a simple light camera. For real-time depth acquisition, the sensor can be thought of as a scanner, one for which a reliable acquisition of a surface depends on the user’s ability to scan all of its obscured corners. In contrast, when a single depth image is acquired, the problem of surface hole-filling becomes a difficult one. Self-occlusion in complex, non-convex, 3-dimensional objects cannot be reconstructed with accuracy and the missing information needs to be interpolated by algorithmic means.
Solutions for three-dimensional surface reconstruction
Surface reconstruction is a challenging problem, and over the years many solution have been suggested, using methodologies from computer vision and machine learning to complete these missing data. The most straightforward approach utilizes surface interpolation, which gives an inaccurate solution for large gaps in the surface. Other methodologies involve the well-known Poisson surface reconstruction, which requires a dense point cloud of orientation vectors to perform well. Despite this limitation, the Poisson surface reconstruction can be used as a framework to reconstruct surfaces for uniform and non-uniform sampling, a situation which is frequently encountered in natural depth acquisition. In the heart of the algorithm lies a minimization process, which attempts to recover a smooth gradient map from the projected point cloud acquired using the depth sensor.
The ripening domain of machine learning provides alternative means to the Poisson surface reconstruction and it enables to simulate empirical expert knowledge in hole-filling. These methods learn the rules of smooth completion of holes, incorporating knowledge of the observed point cloud. One of the most common pipeline for such learning is one for which the depth image (the so-called 2.5D image) is first encoded using 3D primitives (simple spatial shapes) and it reduces the problem surface completion problem into a lower dimensional space, in which constraints on the smoothness of the reconstructed surface can be fulfilled. The completed space is then decoded back to recover the original scene, only this time with holes filled by a primitive shape, or a combination thereof, to the original scene.
At RSIP Vision we tackle the hard problems in computer vision utilizing state-of-the-art tailor-made solutions for our clients. Our engineers stand in the front line of technology to bring our customers the best, most effective and accurate solution to their projects’ needs. To learn more about RSIP Vision’s activities over the past decades, please visit our projects page. To follow the latest trends in computer vision worldwide, subscribe for free to our monthly magazine, Computer Vision News.